0x00 前言
历时三天的速成,终于把报告上交了;
不过话说回来,堆可能是初学者比较难啃的骨头,没什么固定做法,复杂多变;
这里自己记录一些最基本的知识点
后期往里补充一点知识点
0x01 背景知识
堆(heap)是一种全局的数据结构,主要是指用户动态申请的内存(如调用malloc、alloc、new等函数),不同于栈的是,堆具有更多的灵活性,因此堆漏洞的利用也更加复杂,更加零散,在此我总结一下堆溢出漏洞的几种常见的利用方法。
以下是学习堆所需要掌握并熟悉的基本知识点。
glibc malloc中三种最基本的堆块数据结构:heap_info, malloc_state, malloc_chunk;
chunk内存块结构及各字段功能;
bins类型及空闲内存块的管理组织方法;
malloc()、free()工作流程;
0x02 基本漏洞类型
1.常规堆溢出
堆缓冲区溢出与栈缓冲区溢出类似,指堆上的缓冲区被填入过多数据,导致堆中其他数据被覆盖,主要分为两种情况:
(1)覆盖本堆块内部数据,通常发生在结构体中,如果结构体中数组溢出,则覆盖后续变量。
(2)覆盖后续堆块数据,会影响后续堆块的数据,甚至破坏堆块结构。
对于这两种情况可以类比栈溢出原理,没有太多技巧性的知识,但是CTF中不会出现单纯利用堆溢出的题目,通常多种基本漏洞会相互结合,所以要求常见基本漏洞类型都要掌握并且能够灵活使用。
2.Off By One
缓冲区溢出的一种,但是比较特殊,只能溢出1个字节。
有两种利用思路:
(1) 溢出字节为可控制任意字节:通过修改大小造成块结构之间出现重叠,从而泄露其他块数据,或是覆盖其他块数据。
(2) 溢出字节为 NULL 字节:溢出的一个字节恰好覆盖下一堆块的size域的最低位,将PREV_INUSE位置0,这样前块会被认为是 free 块。这时可以选择使用 unlink 方法进行处理(后面将详细介绍),这时 prev_size 域就会启用,就可以伪造 prev_size ,从而造成块之间发生重叠。
下面是一个简单的off by one的程序:
1 |
|
程序很简单,但并非安全,问题在于strlen 在计算长度的时候不会把结束符 ‘\x00’ 计算在内,但strcpy 在拷贝的时候会把 ‘\x00’ 也算上,所以就会造成 off by one。(for循环中也比较常见)
调试一下,便于理解,在main函数下断点,然后单步到输入位置,查看一下chunk情况,

当我们输入24个’A’之后,很明显下一位低字节被覆盖为’\x00’

Note:有一个点要注意,为什么申请了24个字节,chunk大小是0x21呢,也就是说为什么用户数据部分大小只有0x10?
其实是这样的,当前一堆块正在使用时,下一堆块的prev_size也被当作数据部分(大小0x08),只有前一堆块free时,prev_size域才有意义。
3.Use After Free
Use After Free(UAF)即释放后使用漏洞。若堆指针在释放后未置空,形成悬挂指针,当下次访问该指针时,依然能够访问原指针所指向的堆内容,形成漏洞。通常需要根据具体情况分析,以判断是否具有信息泄露和信息修改的功能。
这是比赛时最常规的一种方法,绝大多数题目都要借助它来完成,简单来说当我们第一次申请的内存释放之后,没有进行内存回收,下次申请的时候还能申请到这一块内存,导致我们可以用以前的内存指针来访问修改过的内存。
同样,用一个 UAF的程序展示简单的漏洞利用,以便于理解。
1 |
|
很明显,p1,p2指针指向了同一地址,原因就是p1被释放后,放入fastbin,当p2再次申请同样大小的空间时,直接从fastbin中取出刚刚被释放、且大小合适的内存空间(即p1),以提高分配速度,如果程序员粗心大意,那么就会造成了可以被利用的UAF漏洞。
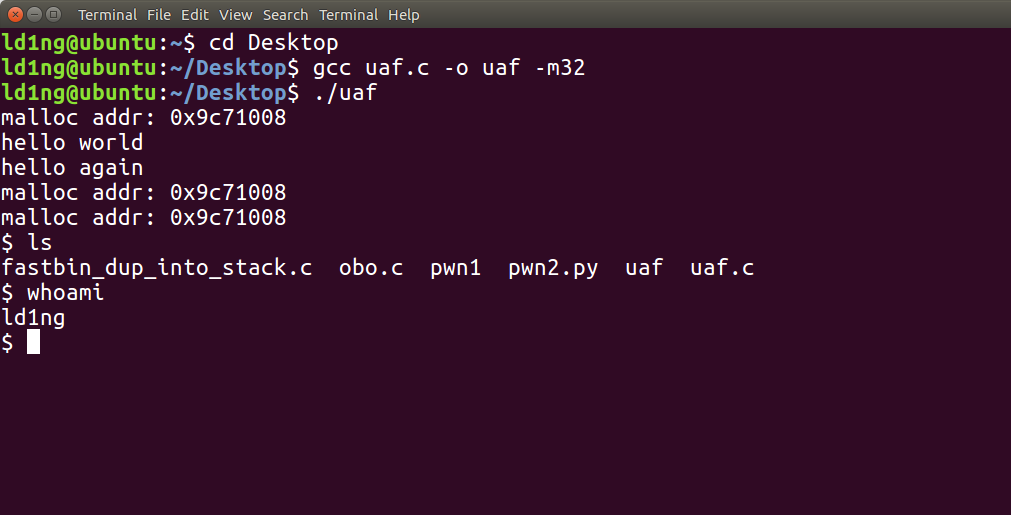
成功获取shell。
4.Double Free
Double Free是UAF较为特殊的一种,也是比赛中经常被使用的基本方法之一,简单的说,double free是任意地址写的一种技巧,要与堆管理的其他特性相结合使用,先不谈利用,这里我只是介绍一下double free最基础的原理。以fastbin为例,fastbin 是 LIFO 的数据结构,使用单向链表实现。根据fastbin 的特性,释放的chunk 会以单向链表的形式回收到fastbin 里面,然后通过 fastbin->fd 来遍历。由于 free 的过程会对 free list 做检查,我们不能连续两次 free 同一个 chunk,所以这里在两次 free 之间,增加了一次对其他 chunk 的 free 过程,从而绕过了检查顺利执行,然后再 malloc 三次,就在同一个地址 malloc 了两次,也就有了两个指向同一块内存区域的指针。
1 |
|
程序free(a)了两次,可以一步一步调试chunk的情况,
三次malloc之后

free(a)之后,可以看到a被加到了fastbin中

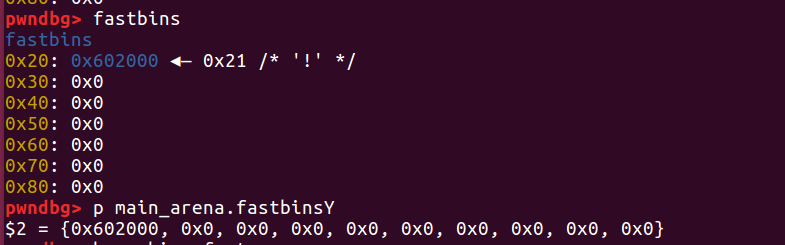
free(b)之后,可以看到b也被加到fastbin中,并且fd指针指向了a的地址
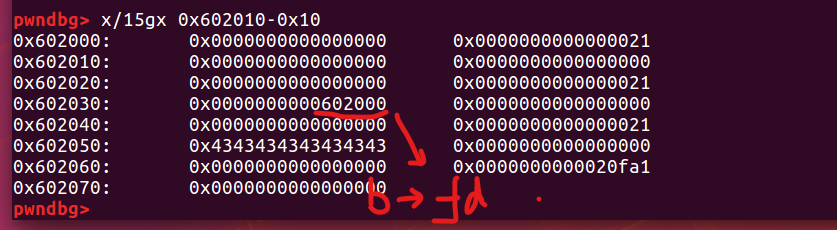
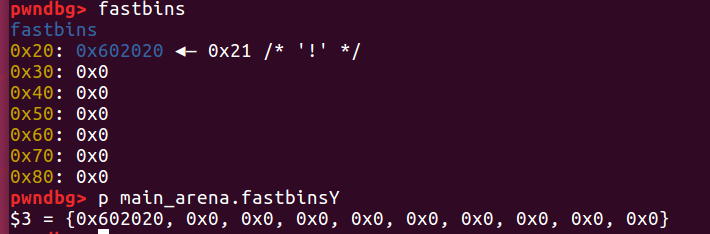
再次free(a)之后,a->fd又指向了b,也就是说a再一次被添加到fastbin,同时b->fd=a,所以实际上形成了一个环。
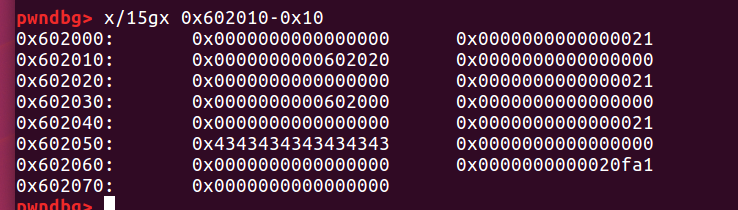
最后三次malloc之后,发现0x44(‘D’)不见了,其实是第二次malloc a的时候0x46将其覆盖了。这就是double free的基本原理,但可以想象,如果第一次申请a的时候,将fd指针修改成有意义的地址,那么我们就可以做到任意地址写(可以结合堆溢出)。

在 libc-2.26 之后,即使两次 free,也没有触发 double-free 的异常检测,这是因为 tcache 的机制有关,水平有限,这里暂不探讨。
0x03 堆溢出漏洞利用
1. House of spirit(fastbin)
利用技术:
(1) fastbin 为单链表(只用到fd),结构简单,容易伪造
(2) 为了提高分配效率,安全检查少
(3) 只针对fastbin大小的chunk,small/large chunk不适用
(4) 存在堆溢出、use-after-free 等能控制 chunk 内容的漏洞
利用思路:
空闲fast chunk如果发生溢出被覆盖,则链表指针fd可以被修改
通过修改链表指针fd,在fastbin中引入伪造的free chunk(最重要的是必须保证伪造的chunk结构合法)
下次分配时分配伪造的fast chunk
伪造的fast chunk可以在以下位置:
在栈上伪造fast chunk:覆盖返回地址
在bss上伪造fast chunk:修改全局变量
在堆上伪造fast chunk:修改堆上数据
以fastbin_dup_into_stack为例,该程序便是利用double free进行fastbin attack其余两种可类比该例子
1 |
|
这个程序展示了怎样通过修改指针,将其指向一个伪造的 free chunk,在伪造的地址处 malloc 出一个 chunk。Double free之前的程序基本没变,关键点在于我们的下一次malloc:
1 | unsigned long long *d = malloc(9); |
填充了一个地址:栈地址-0x8
这一步的意义就是在于在栈上构造了一个合法chunk,伪造的chunk要有合法的堆头信息,所以应从size域-0x8开始。
特别要注意的是,fake fastbin中的size需要与改写指针的fastbin块大小一致,且p位为1。
可以看一下栈中的位置
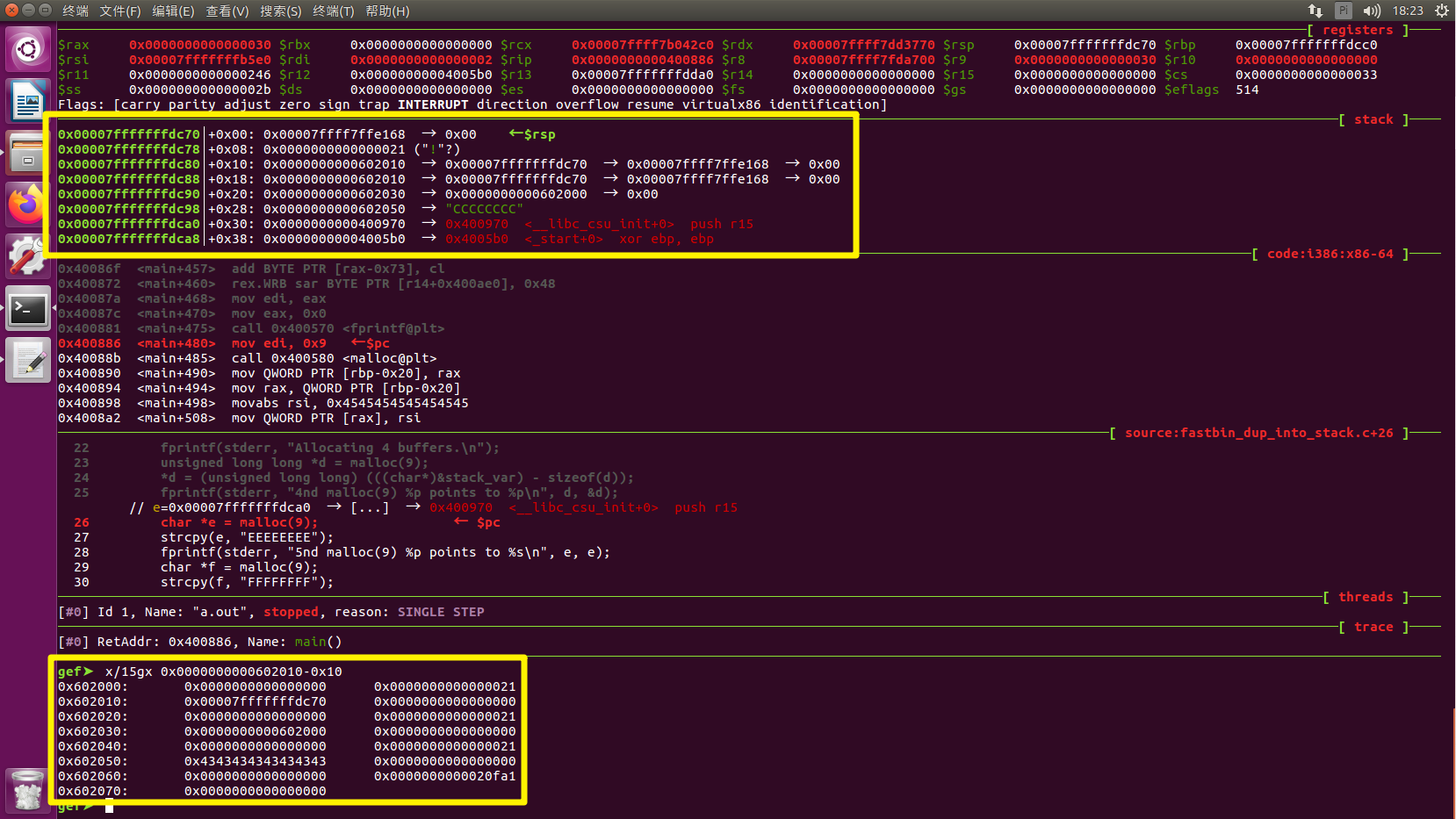
而在fastbin中,原本的a堆块fd指针已经改为栈中对应的地址,因此当下一次malloc a时,就会在我们伪造的假chunk分配内存。
如果能实现在栈中的任意地址写,那么就可以用栈的方法获取shell。
同样,如果存在堆溢出漏洞,也可以进行free chunk fd指针的修改,但是为了总结相关原理和便于理解,我举的例子都很简单,仅适合入门者学习参考。
2. house of force
利用条件:
1.能够以溢出的方式控制到top chunk的size域
2.能够自由地控制堆分配尺寸的大小
3.可以构造size拿到top chunk本身之外的内存,如libc的内存空间
这种方法主要是指堆块溢出覆盖top chunk中的size域的情况,通过将其修改为一个非常大的数据,从而可以申请非常大的空间,使得新top chunk的头部落到想要修改的位置。在下次申请时,就能够得到目标内存,从而实现泄露和改写。
利用步骤如下:
(1)首先先泄露出堆地址。
(2)利用堆溢出,将top chunk的size域修改为很大的数
(3)申请大块内存(可以通过堆地址和目标地址的距离进行计算),使得top chunk的头部落在目标地址范围内。
(4)再次申请内存,那么新申请的内存即为目标地址,通常情况下(未开启FullRelro),一般是将目标地址设为got表地址。
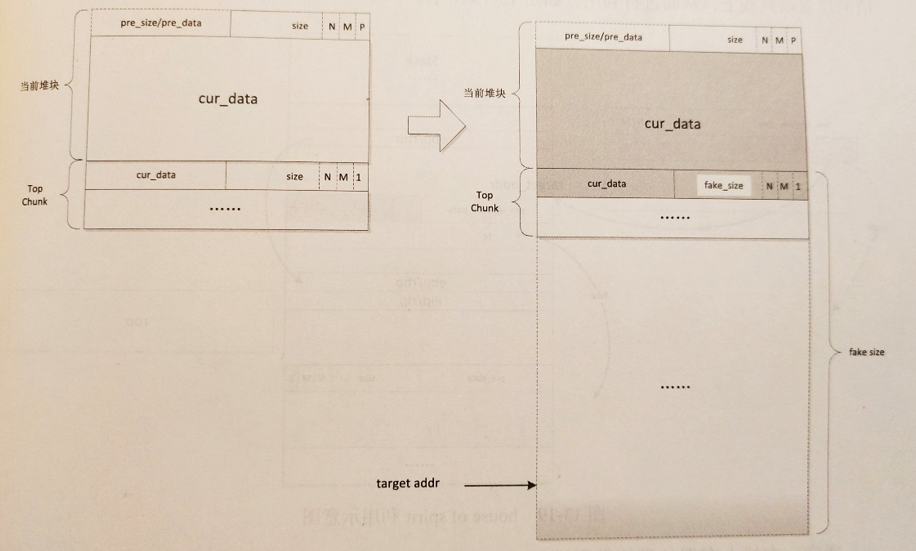
当我们计算好当前堆块与目标地址之间的偏移后,申请该大小的堆块,让chunk头会恰好落在目标地址前(低地址),这时再次申请,我们就可以改写目标地址内容。
3.unlink(旧版)
unlink攻击技术是利用glibc malloc的内存回收机制,通过堆溢出等方法进行内存修改。
要想利用unlink,首先要了解free()的工作过程:
(1)如果size<max fast,放入fastbin,结束
(2)如果前一个chunk是free的,unlink前面的chunk,合并两个chunk,并放入unsorted bin
(3)如果后一个chunk是free的,则unlink后面的chunk,合并两个chunk,并放入unsorted bin
(4)如果后一个是top chunk,则将当前chunk并入top chunk
(5)前后chunk都不是free的,则直接放入unsorted bin
相关代码如下:

流程大体是这样的:
(1)将前一个chunk占用的内存合并到当前chunk;
(2)修改指向当前chunk的指针,改为指向前一个chunk。
(3)使用unlink宏,将前一个free chunk从双向循环链表中移除
向前合并和向后合并过程类似,这里不再赘述。了解了unlink的基本原理之后,可以结合例子理解
存在unlink攻击漏洞的程序如下
1 |
|
该程序存在一个堆溢出漏洞:如果用户输入的argv1的大小比first变量的666字节更大的话,那么输入的数据就有可能覆盖掉下一个chunk的chunk header——这可以导致任意代码执行。而攻击的核心思路就是利用glibc malloc的unlink机制。
现在我们再来分析如果一个攻击者精心构造输入数据并通过strcpy覆盖了second chunk的chunk header后会发生什么情况。
假设被覆盖后的chunk header相关数据如下:
(1) 填充prev_size位为一个偶数
(2) size = -4 (64位下为-8)
(3) fd = free 函数的got表地址address – 12;
(4) bk = shellcode的地址
那么当程序调用free(first)后会发生什么呢?
我们一步一步分析,前面已经介绍过了free的流程,由于first前面无free的chunk,所以不会发生向后合并,因此来判断下面是向前合并,代码如下:

本例中,next chunk就是second chunk,从上面代码可知chunk判断下一堆块是否free的方法,即通过nextchunk + nextsize计算得到指向下下一个chunk的指针,然后判断下下个chunk的size的PREV_INUSE标记位是否为0。
在本例中,此时nextsize被我们设置为了-4,这样glibc malloc就会将next chunk的prev_size字段看做是next-next chunk的size字段,而我们已经将next chunk的prev_size字段设置为了一个偶数,因此此时通过inuse_bit_at_offset宏获取到的nextinuse为0,即next chunk为free!
既然next chunk为free,那么就需要进行向前合并,所以就会调用unlink(nextchunk, bck, fwd)函数。
真正的重点就是这个unlink函数的利用,认真分析一下unlink的代码

打眼一看,很像数据结构中学过的删除链表中某一结点的操作,确实如此,unlink实现的功能正是在bins链表中删除掉已经被合并的块。
具体利用流程如下:
(1) 首先FD = nextchunk->fd = free地址 – 12;
(2) 然后BK = nextchunk->bk = shellcode起始地址;
(3) 再将BK赋值给FD->bk,即(free地址 – 12)->bk = shellcode起始地址;
(4) 最后将FD赋值给BK->fd,即(shellcode起始地址)->fd = free地址 – 12。
作图理解一下:
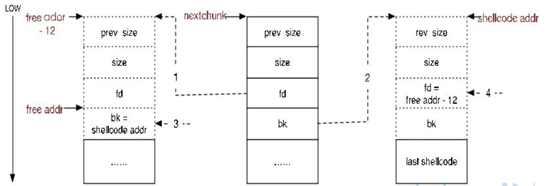
结合图片应该很好理解,借助了unlink将free()的got表修改为shellcode地址,当再次free(second)时,就会转而运行我们写好的shellcode了。
这里的chunk头并不是真实的,只是我们在攻击中需要让glic malloc在进行unlink时将它们强制看作chunk结构体而伪造的,也就是我上面说的结构合法。
4.unlink (freenote)
上面Unlink的方法有些过时,但是可以拿过来学习一下原理,有助于对堆有更好的理解,目前新式的unlink中加入了许多限制,其中最重要的一条是:
FD->bk !=p || BK->fd !=p;
也就是说由于有一个保护检查机制,它会检查这个 chunk 的前一个 chunk 的 bk 指针是不是指向这个 chunk(后一个也一样),直接导致很多利用方式难以满足这个条件,比较有效的是freenote的方式。
下面介绍freenote的主要利用思路。
Free chunk 的双链表结构如下所示:
FD = p->fd = *(&p + 2)BK = p->bk = *(&p + 3)
但现在执行unlink(P,BK,FD)时,需要满足FD->bk = p && BK->fd = p的条件,即:
FD->bk = *(*(&p + 2) + 3 ) = *(p[2] + 3) == p
BK->fd = *(*(&p + 3) + 2 ) = *(p[3] + 2) == p
=>p[2] = &p – 3, p[3] = &p – 2
这里比较绕,建议画图辅助理解。
这时如果存在一个全局变量G_P,其中存储的指针指向p的话,那么就可以通过设置p[2] = &p – 3, p[3] = &p – 2 进行伪造,来满足指针检查。

根据图所示,当构造的fake chunk溢出修改了下一个chunk的 prev_size和p位,就可以将fake chunk 伪造成free chunk,这时free掉下一个chunk,两个块便可合并,触发unlink。
FD = P->fd
BK = P->bk
FD->bk = BK
BK->fd = FD
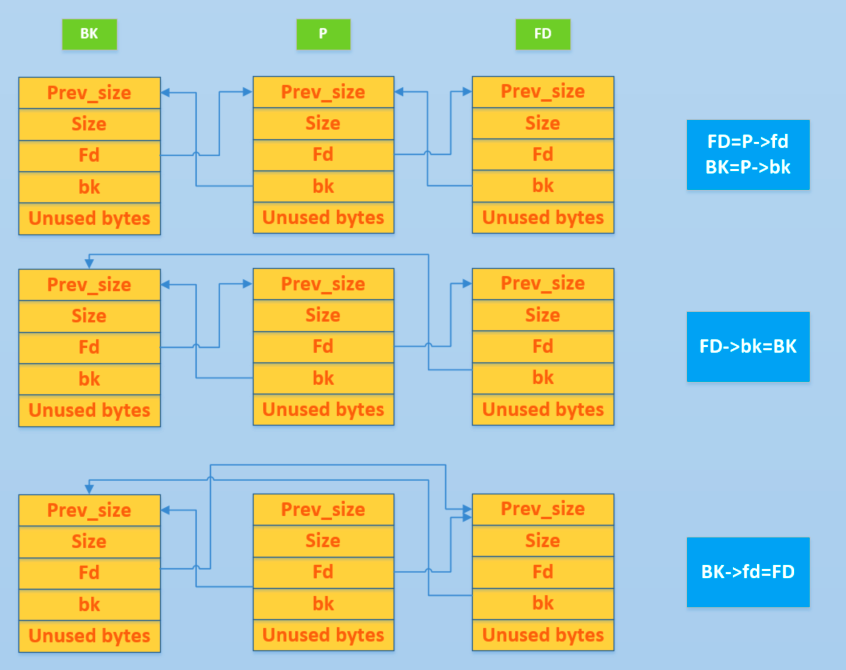
最终执行:
FD->bk = BK; =>p = *(&p+3) = p[3] = &p-2
BK->fd = FD; =>p = *(&p+2) = p[2] = &p-3
使得:p= &p – 3
最后,p指针指向全局变量G_P前面3个4(8字节)字节处。如果G_P是个管理结构,那么就可以实现任意地址读写了。即可以通过修改p所指向的内容来修改p的指针了
需要满足如下条件:
存在堆覆盖,可以改写到即将要释放的堆块,将其prev_size改成所构造的堆块大小,size中p位改为0.
存在已知地址的指针(通常为全局变量)指向伪造的堆块头部。
能够释放后续堆块来触发unlink。
5.forgotten chunk
forgotten chunk主要是指chunk的申请释放中被遗忘的部分,虽然堆块的申请和释放逻辑相对来说比较完善,但是检查还是存在漏洞。
简单的情况是从前往后释放,构造出残留堆块。
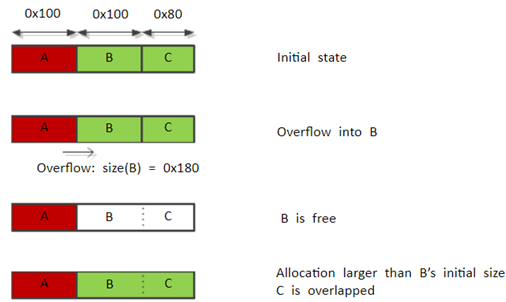
如图所示,如果存在缓冲区溢出,然后通过正常申请释放构造出重叠堆块。
对于已经使用的A,B,C三个堆块,在大小方面没有要求,其中如果A存在堆溢出,且能够覆盖到堆块B的size域(或存在其他改写方式也能达到相同目的),将堆块B的size域的部分改写成size(B)+size(C)的值(NMP位保持不变),然后对堆块B进行释放,这样是可以通过检查的,并且能将B,C识别成一个堆块进行处理。其中原本C后续堆块的prev_size域会被当成数据部分处理,不起标识作用,使检查能顺利通过。
在此基础上,可以结合最基本的堆利用方法、unlink、fastbin来对堆块进行利用。
(1) 如果C块或者其上还有其他未知块部分存在变量指针,则采用最基本堆利用方法,直接构造指针数据即可。
(2) 如果存在fastbin中的堆块,且其中想改写的目的地址符合fastbin利用条件,则采用fastbin的方法。
(3) 直接申请新堆块,在其中构造unlink利用的条件,通过释放堆块来触发unlink。
具体利用什么方法视情况而定。
7. tcache利用
2.27的libc不再多说,基本没有任何检查,可以直接构造double free。
在libc-2.29,tcache添加了新的检测机制,相关的源码如下
1 | //glibc-2.27 |
1 | //glibc-2.27 |
tcache机制首先会在heap开头位置创建一个tcache_perthread_struct结构体来维护:
1 | typedef struct tcache_perthread_struct |
其前0x40字节为对应大小tcache的数量,后0x200个字节为指针数组,指向tcache_entry链表的头部指针
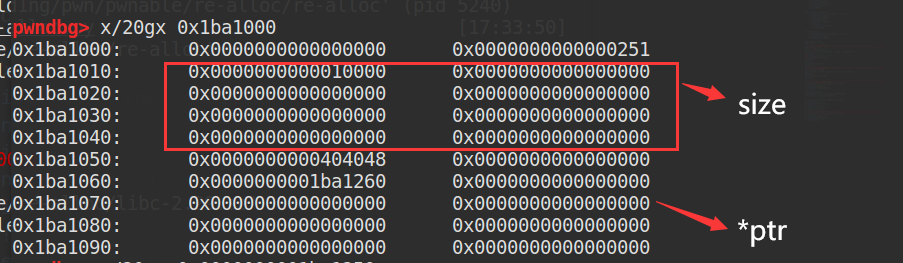
当chunk被free到tcache中时,key会被置为tcache_perthread_struct的地址,也就是heap开头的位置。当chunk从tcache中取出来时,key会被设置成NULL。总而言之,就是通过key来表明这个chunk是否在tcache中。
而这个key也是libc2.29中提供的对tcache的额外的检查,即在将一个chunk放入tcache时,会检查该chunk的key是否等于tcache结构体的地址,如果是,则进一步检查tcache中是否已有地址相同的chunk,从而触发double free的检查机制。
若key为0或者修改chunk的大小,使chunk的size不在该tacache内,即可再次造成doublefree。
这里记录另一种高版本tcache的利用,叫作Tcache Stashing Unlink Attack。glibc-2.29 samllbin范围内的申请流程:
1 | if (in_smallbin_range (nb)) |
从small bin中取出最后一个chunk的时候,对双向链表做了完整性的检查,然而,后面将剩余chunk放入tcache bin的时候,却没有这个检查。因此只要修改smallbin中最后一个chunk的bk为target地址,那么通过完整性检查后,它就被放入tcache中,就可以将target申请出来进行利用。
值得注意的一点是,需要使用到calloc(),可以绕过tcache,直接申请smallbin。因此该方法的利用条件为可以控制smallbin的bk,存在一条tcache bin(未满)和两个相同大小的smallbin存在的时候,通过calloc函数申请此大小的堆块触发将后一个smallbin中的堆块插入tcachebin链中。
glibc2.32引入的新的防御机制-safe-linking(异或加密) 参考,tcache链也从7个增到16个
1 |
也就是说此时chunk的fd为 (&(p2->next)>>12) ^ &p1,自己的地址>>12 ^ fd
glibc2.34之后取消了free_hook malloc_hook等
8. unsorted bin attack
双向循环链表,先进先出,以下几种情况会分到 unsorted bin 中
1、当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中
2、释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中
3、当进行 malloc_consolidate 时,可能会把合并后的 chunk 放到 unsorted bin 中,如果不是和 top chunk 近邻的话
unsorted bin attack 实现了把一个超级大的数(unsorted bin 的地址)写到一个地方
利用方法,修改unsorted bin中chunk的bk为目标地址-0x10,再去将其申请出来时进行以下操作:
1 | /* remove from unsorted list */ |
最终target地址-0x10的位置就被写入了unsortedbin的地址 (unsorted_chunks (av))
9. large bin attack
堆块管理器中最慢的一种管理方式,largebin 的范围是 size > 0x400(x64)
large bin 采用双链表结构,里面的 chunk 从头结点的 fd 指针开始,按大小顺序进行排列。且不同的序号的largebin的差值不同(0x40*32,0x200*16,0x1000*8,0x8000*4,0x40000*2)
其chunk结构:
1 | struct malloc_chunk { |
为了管理的高效,在纵向链表(fd_nextsize/bk_nextsize)中,堆管理器维护一个循环的单调链表,由最大的 size(在这个 index 下的最大 size)作为表头,最小的 size 作为表尾,且首尾相连。
遍历unsortedbin代码如下:
1 | if (in_smallbin_range(size)) |
当已经存在一个largebin Y和unsortedbin X,那么再申请一个堆块就会触发unsortedbin脱链,让unsortedbin中chunk插入到largebin中,如果满足 size (X) > size (Y) && index (size (X)) == index (size (Y)),那么 X 就会插入到 Y 的前面,从而触发这一串代码进行插入。
1 | //victim是X、fwd是修改后的Y |
把 2 带入 4 得到:fwd->bk_nextsize->fd_nextsize=victim
同时下面有:bck->fd = victim;(bck 也就是 fwd->bk)也就是说之前我们伪造的Y的 bk->fd 跟 bk_nextsize 指向的地址被改为了 victim,即 tartget1 + 0x10与target2 + 0x20 被改为了 victim
2.30以下存在一个利用方法叫作House_of_storm,House_of_storm是一种结合了unsorted_bin_attack和Largebin_attack的攻击技术,其基本原理和Largebin_attack类似,但是不同的是Largebin_attack只可以在任意地址写出chunk地址实际应用中除了泄漏一个堆地址并没有什么其他用处,所以其基本无害。而House_of_storm则可以导致任意地址分配chunk,也就是可以造成任意地址写的后果。
漏洞利用条件:
1.需要攻击者在largebin和unsorted_bin中分别布置一个chunk 这两个chunk需要在归位之后处于同一个largebin的index中且unsortedbin中的chunk要比largebin中的大
2.需要unsorted_bin中的bk指针可控
3.需要largebin中的bk指针和bk_nextsize指针可控
相较于
Largebin_attack来说 攻击需要的条件多出了一条“unsorted_bin中的bk指针可控”,相当于unsortedbin attack + largebin attack
- unsorted_bin->bk = fake_chunk #把fake_chunk链到了unsorted_bin中
- fake_chunk+0x10 = unsorted_bin #伪造fake_chunk的fd
- fake_chunk+0x3 = unsorted_chunk #伪造fake_chunk的size
- fake_chunk+0x18 = unsorted_chunk #伪造fake_chunk的bk
1 | // gcc -ggdb -fpie -pie -o house_of_storm house_of_storm.c |
所以当我们申请的size和0x56经过对齐后相等的话,那么就可以拿到任意的chunk。
0x55 : 1010101
0x56 : 1010110
__int_malloc在拿到chunk后返回到__libc_malloc,__libc_malloc会对chunk的进行检查,这里如果有错的话会直接crash,但是由于程序有随机化,多运行几次总能有一次成功的。
利用 large bin attack 分别错位写一个 size 和 bk 的地址,size 错位写了 0x56(由于 pie 的原因,chunk 的地址总是为 6 字节,但是头部地址可能是 0x55 或者 0x56,这里需要 0x56 才能成功,因为 malloc 后会进行检测)
以下检测需要满足的要求,只需满足一条即可
1 | /* |
利用 unsorted bin attack 在 fd 的位置写一个 main_arena + 88 的地址,从而绕过了检测。
10. House of Orange
总体流程:
- 题目中没有free,那么通过修改top chunk的size为一个小数,再申请一个大于该size的堆块,那么系统会调用sysmalloc通过brk拓展 top chunk,其中就会free掉old_top_chunk。
- 通过修改bk进行unsorted bin attack修改_IO_list_all为unsorted bin地址(main_arena+88)
- 同时在可控的unsorted bin里伪造0x60大小的IO_file_plus和 vtable 结构
注:需要伪造0x60大小的字段,原因是unsorted bin attack之后_IO_list_all改为main_arena+88的地址,我们并不可控,而*chain域的偏移是0x68,main_arena+88+0x68刚好是small bin的0x60大小,将unsorted bin中的chunk的size修改为0x60且在old top chunk中布置伪造的IO_FILE,写入之后,再进行申请时,因为大小不合适unsorted bin chunk就会被链入smallbin的0x60数组中,即伪造的堆块被放入了IO_FILE结构体链表中,由于unsorted bin结构被破坏,所以在之后的检测发生了报错,这个报错就会调用到_IO_flush_all_lockp,而这里就会对_IO_list_all 进行遍历,调用 _IO_OVERFLOW (fp, EOF) getshell。
1 | /* remove from unsorted list */ |
当glibc检测到内存错误时,会依次调用这样的函数路径:malloc_printerr -> libc_message->__GI_abort -> _IO_flush_all_lockp -> _IO_OVERFLOW,_IO_flush_all_lockp 会把 _IO_list_all作为链表头开始遍历,并把当前节点作为 _IO_OVERFLOW 的参数。

伪造 fp->_mode = 0, fp->_IO_write_ptr > fp->_IO_write_base来通过验证即可
64位的_IO_FILE_plus构造模板:
1 | stream = "/bin/sh\x00" + p64(0x61) |
32位的_IO_FILE_plus构造模板:
1 | stream = "sh\x00\x00"+p32(0x31) # system_call_parameter and link to small_bin[4] |
64位下seccomp禁用execve系统调用的构造模板:
1 | io_list_all = libc_base+libc.symbols['_IO_list_all'] |
将函数控制流控制在 setcontext+53 的位置,是因为这里正好可以修改 rsp 到我们的可控地址来进 行 rop,在切栈之后就可以按照如上过程执行 rop。 首先调用 mprotect 函数将 当前 heap 段设置为可执行,然后调用 cat flag 的 shellcode。
glibc2.24:
在_IO_OVERFLOW做了小小的改动,IO_validate_vtable增加了虚表范围的检查,也就是虚表地址必须位于__start___libc_IO_vtables和__stop___libc_IO_vtables之间,显然之前在堆中伪造的虚表不满足要求。

方法一:利用_IO_str_overflow
虽然不能把vtable改到堆上了,但是我们依旧可以改 vtable为_IO_str_jump来绕过检测(_IO_str_jump这个虚表位于上面的范围之内),因为其中使用的IO_str_overflow 函数会调用 FILE+0xe0处的地址。这时只要我们将虚表覆盖为_IO_str_jumps将偏移0xe0处设置为one_gadget即可。
1 | // libio/strops.c |

需要满足的条件是:
1 | 1.fp->_flags & _IO_NO_WRITES为假 |
方法二:利用_IO_str_finish

需要满足的条件是:
1 | fp->_IO_buf_base为真,(fp->_flags & _IO_USER_BUF)为假 |
利用之前的House of Orange,将vtable改为_IO_str_jumps - 0x8,因为_IO_str_finish在_IO_str_jumps的偏移与在中偏移不同。

由于 _IO_str_jumps 不是导出符号,因此无法直接利用 pwntools 进行定位,我们可以利用 _IO_str_jumps中的导出函数,例如 _IO_str_underflow 进行辅助定位,我们可以利用gdb去查找所有包含这个_IO_str_underflow 函数地址的内存地址,如下所示:

再利用 _IO_str_jumps 的地址大于 _IO_file_jumps 地址的条件,就可以锁定最后一个地址为符合条件的 _IO_str_jumps 的地址,由于 _IO_str_underflow 在_IO_str_jumps 的偏移为0x20,我们可以计算出_IO_str_jumps 的地址。
1 | def get_IO_str_jumps(): |
彩蛋:glibc2.29的虚表可写!

最后记录一下malloc_state结构和malloc和free的流程:
1 | malloc_state就是内存中用来管理堆的数据结构,源码中表现形式如下 |
ptmalloc2共有127个bin。其中62个small bin,64个large bin以及一个unsorted bin。malloc_state的bins数组存放了所有的bins信息(除tcache)
其中bin[0]bin[1]保存了unsorted bin链表的头指针.bin[2]和bin[3]合起来指示了一个bin双链表就是堆的第一个small bin,其中bin[2]是头指针,bin[3]是尾指针。
malloc:
1.如果size < max fast, 在fast bins中寻找fast chunk, 如找到则结束
2.如果(if) size in_ smallbin_ range, 在small bins中寻找small chunk,如找到则结束
3.如果(else) size not in_smallbin_ range, 合并所有fastbin的chunk
4.循环
—a.检查unsorted bin中的last_remainder(初始为0)
如果满足一 定条件,则分裂之,将剩余的chunk标记为新的last remainder
—b.在unsorted bin中搜索,同时进行整理
如遇到精确大小, 则返回,否则就把当前chunk整理到small/large bin中去.
—c.在small bin和large bin中搜索最合适的chunk (不一定是精确大小)
5.使用top chunk
通常这里会使用到unsorted bin分割的手法,即已有unsorted bin,再次申请一个小堆块,如果没有满足条件的堆块就进入4.循环,一般初始last_remainder为0,所以跳过步骤a,将此unsorted bin整理进入small bin(或large),然后进行步骤c,将small bin分割并分配出来( 此时该堆块中残留smallbin的地址,可用于泄露libc ),剩下的则进入unsorted bin,标为last_remainder。再次分割unsorted bin时,此时last_remainder存在,则进行步骤a。
free:
1.如果size < max fast,放入fast bin,结束
2.如果前一个chunk是free的
—a. unlink前面的chunk
—b.合并两个chunk(向后合并), 并放入unsorted bin
3.如果后一个chunk是top chunk,则将当前chunk并入top chunk(向前合并)
4.如果后一个chunk时free的
—a. unlink后面的chunk
—b. 合并两个chunk(向前合并),并放入unsorted bin
5.前后chunk都不是free的,放入unsorted bin
0x04 小结
堆的利用灵活多变,且情况比栈的利用复杂的多,我所记录的只是一些最基本且常见的方法,便于对堆溢出漏洞利用有一个比较客观的认识,至于更多技巧,则需要自己不断实践和学习积累来获得。
